

Audio By Carbonatix
Will ChatGPT Transform International Development?
After the spectacular failure of a 10-year project launched in 1982 by the legendary Japanese government agency, MITI, to dominate the global artificial intelligence (AI) landscape by developing systems suited to processing knowledge (rather than just data) in a user-friendly way, the country tried another approach.
In 1998, six years into the successor initiative, dubbed Real World Computing Program (RWC), publisher Ed Rosenfeld reported on an exhibition in Tokyo where the new project’s outcomes were on display. The goal, according to project managers, was to create a system to enable:
“humans to communicate easily with computers …[by the] implementation and refinement of “natural and smooth” interfaces through talking, facial expressions, and gestures.”
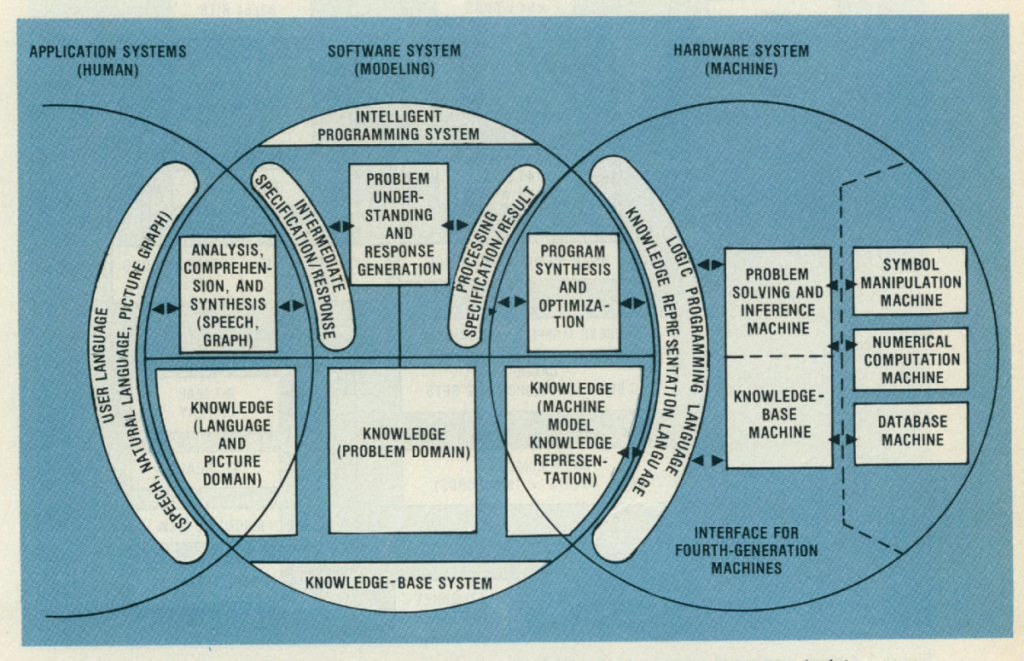
Essentially upping the stakes on the earlier attempt. Unfortunately, RWC failed to charm, and soon slunk into oblivion. Japan’s 20-year AI domination strategy was nevertheless focused on two still-dominant narratives of the role of “thinking machines” in shaping our world. First, “expert systems” to solve human-defying problems and, second, “naturalistic interfaces” to make non-expert humans feel warm and fuzzy around a superior artificial intelligence. Some say that on both scores, ChatGPT has almost delivered.
ChatGPT’s triumphant launch thus resurrects the old dreams, debates and divisions that ensued when a political scientist called Herbert Simon, with no formal training in computing, helped set up a department at Carnegie Mellon University (then known as “Carnegie Tech”) that would become a pioneer in an early branch of practical AI called “expert systems”. In January of 1956, the year in which the Carnegie computing department was founded, Herbert stood before a class of wide-eyed students and proclaimed the invention of a “thinking machine”.

But Herbert’s interests were far from confined to the logical construct of computing devices. His interests were in “psychological environments” and how these could be programmed to optimise human organisation for social change. When eventually he was awarded the Nobel Prize, it would be for his contributions to ideas at the root of today’s behavioural economics (despite not having been a trained economist), such as the optimisation of decision-making under uncertainty and other knowledge constraints.
“Expert systems” were the culmination of these concepts. Envisaged as holding large volumes of structured information assembled by knowledge engineers after extensive interactions with human experts, they would still operate within real-world problem-definition constraints. Through complex, yet programmable, heuristics, such machines would solve problems faster and better than humans. But
Eventually, other branches of AI emerged where the rules of reasoning and analysis emerged from the body of assembled knowledge (or data, to be more liberal) itself instead of a compact heuristics or rules engine. One particular version of this AI model called “Large Language Models” (LLMs) power ChatGPT.
LLMs take the “self-organising” concept to an extreme in the sense that massive increases in data scale appear to have a correspondingly massive effect on the AI system’s cognitive level, a marked departure from the original visions of Herbert and the other expert systems enthusiasts who believed that progress was in the direction of ever more sophisticated rules & heuristics engines.
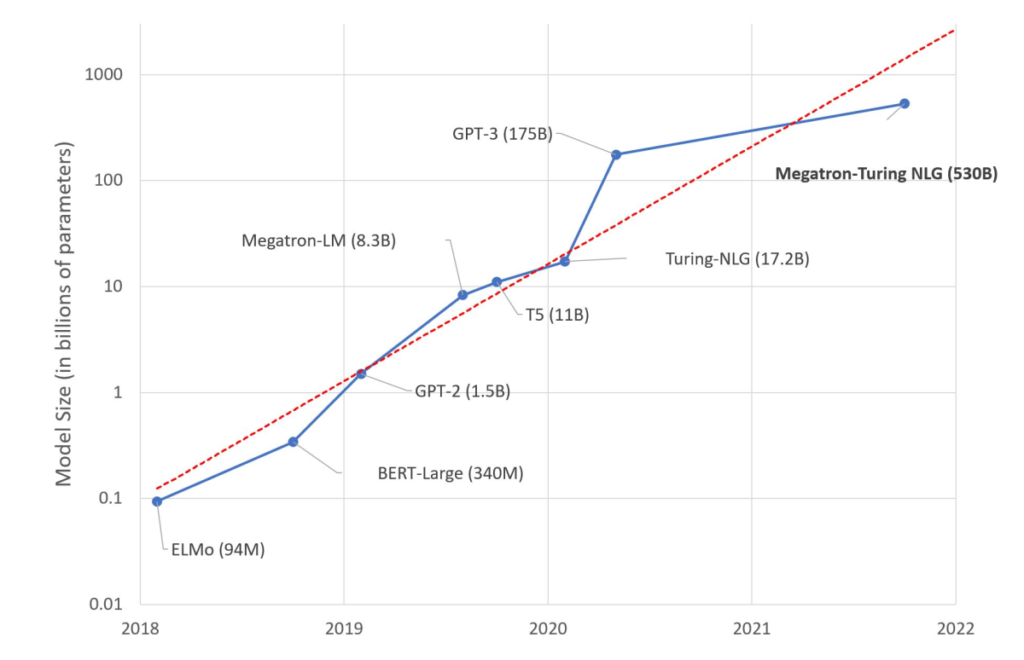
Source: Julien Simon (2021)
What does all this mean for the future of knowledge-based social change? In the field of social innovation for development, where this author plies his trade, old conversations about how expert systems could turbocharge social and economic development have resurfaced.
In 1996, when US academic Sean Eom conducted a survey of expert systems in the literature, he found a field thoroughly dominated by business.
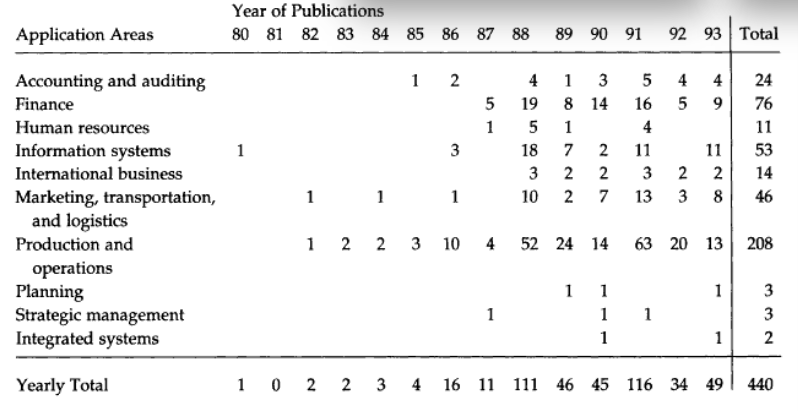
Most of these systems targeted repetitive operational procedures. But a small subset was in use by consultants who focused on strategic open-ended questions, such as one may encounter in economic and social development contexts.
As the 90s unfolded, potential synergies among strategic problem-solving, expert systems and international development frameworks ignited a strong interest in Western agencies.
For example, a review by Dayo Forster in 1992 for a major Canadian Aid Agency in the health context was motivated by the prospect of “maximum productivity” in the face of the appalling scarcity of resources in the developing world. Health has always been of great interest in the AI-for-Development community because of the importance of precise knowledge-based decisions, both at the public health level (for example: what is the right interval between vaccine doses?) and individual health level (is this drug right for this woman given her or her family history?) For this reason, knowledge-enabled decision-makers make most of the difference in outcomes.
Then as now, the promise of cost-effective thinking machines filling in the massive vacuum of local expertise in fields such as health, education, agriculture and planning is the most tantalizing prospect. Consider the case, for instance, of Liberia, which has just 300 doctors at home for a population of 5.3 million (up from 25 at home in 2000 when the population was ~3 million). There are two psychiatrists, six ophthalmologists, eleven pediatricians, and zero – yes a grand zero – urologists. Imagine the good that can be done if an expert system or similar AI could boost the productivity of each of these specialists ten-fold.
Sadly, this first wave of optimism faded slowly until a new turn in AI, anchored on Natural Language Processing (the umbrella group to which LLMs belong), started to produce the kind of results now on display in ChatGPT. The traditional concepts of expert systems were seen as a dead-end, and a ferment of new directions bloomed. ChatGPT’s wild popularity in 2022 marks it as a potential dominant AI design format, despite machine learning’s wider, installed base and committed investments.
Echoing the hopes of times past, a recent McKinsey report by the global consultancy claimed that “[t]hrough an analysis of about 160 AI social impact use cases,” they have “identified and characterized ten domains where adding AI to the solution mix could have large-scale social impact. These range across all 17 of the United Nations Sustainable Development Goals and could potentially help hundreds of millions of people worldwide.”
Until ChatGPT’s dramatic entry into the popular consciousness, investment commitments and revenue forecasts for AI heavily emphasised machine learning applications far more relevant for the Global North than the Global South.
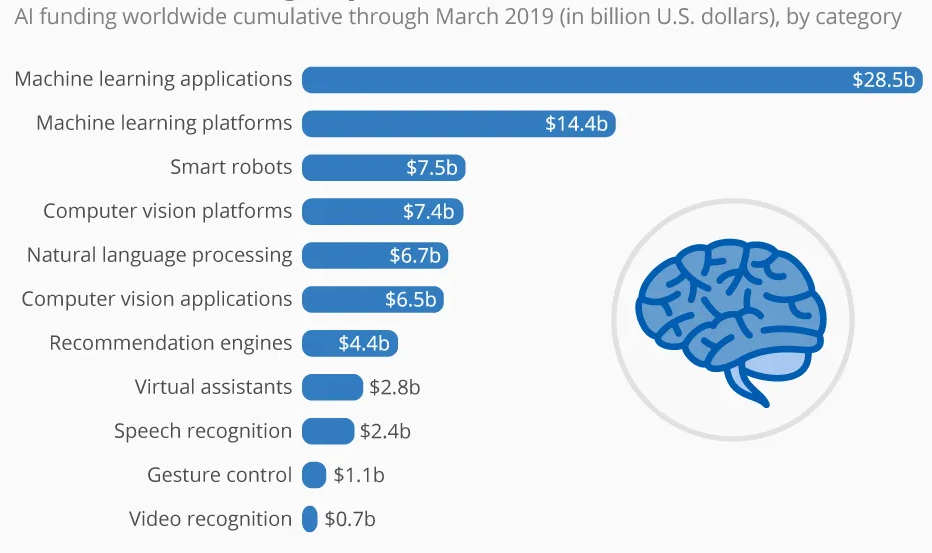
ChatGPT’s “expert systems” – like behaviour in the perception of the lay public however now throws into sharp relief the prospect of low-cost NLP-powered general problem-solving solutions, a kind of multipurpose social development consultancy in a box.
Prospects for Gambia, Liberia or Laos dramatically boosting human resource potential by deploying LLM-powered bots to social service frontlines are suddenly looking exciting again. Or are they?
Below I present a very condensed argument of why ChatGPT and other big-data-driven models, monumental technological feats though they are, lack some vital attributes to make much of a difference soon. These concerns are not addressed by improvements in accuracy and efficiency expected in GPT-4 or later models because they go to the very roots of the philosophy behind such tools. They can only be solved in the technology governance layer.
Expert systems are heavily weighted
LLMs and similar big data-driven systems are about statistical averages. They take snapshots of internet-scale caches of data and then make safe bets as to the most likely answer to a query. The best experts are, however, top-notch for the very reason that they generate insights in the tails of the distribution. It is still too risky to introduce strong weighting in LLMs to generate positive biases since the goal is to minimize bias in general.
Knowledge Engineering is tough
For any complex assignment, a schema of multiple parts involving multiple strands of enquiry produces the most sophisticated outcome. One needs to orchestrate multiple prompts to get ChatGPT to generate the right sequence of answers and then piece them together. This requires higher order, not lower order, cognition. Costs thus shift from expensive specialists to expensive generalists.
For example, a detailed review of ChatGPT’s recent performance on a Wharton MBA test emphasised the critical importance of “hints” from a human expert in refining the bot’s responses. As will be shown later such “prompt loops” cannot be woven unless the expert has strong generalist competence in the area of inquiry.
Factual Precision is less useful than Contextual Validity
Whilst there is a lot of general information available on the internet and from other open sources, a great deal of the world’s contextual insights are still in proprietary databases and in people’s heads. LLMs need extensive integrations to access true insights into most socioeconomically important phenomena. In a 2019 working paper, this author broke down the generic structure of modern computing systems into “data”, “algorithms” and “integrations”, and explained why integrations are the real driver of value. Yet, integrations also limit quality data growth in LLMs like ChatGPT and introduce risks whose mitigations constrain automation efficiency.
Much has been made of ChatGPT successfully passing exams set for advanced professionals such as medical license assessments. In actual fact, a standardised exam taken under invigilated conditions is the worst example to use in the analysis of real-world expertise. First, exams of that nature are based on a syllabus and wrong and right are based on well defined marking schemes designed to approximate statistical yardsticks of performance. It is considerably easier to span the universe of knowledge required to pass an exam and to reproduce “standard quality” answers than it is to operate within the constraints of a turbulent environment such as a field hospital in Liberia. Whilst we use such exams to screen humans for similar jobs, the confidence arises from implicit assurances of their social adaptability in knowledge application.
Proprietary data is expensive
To address the proprietary data and tacit knowledge issues, LLMs will have to compete aggressively for integrations, raising their costs of deployment and maintenance, and thus lowering accessibility for the poor. Already, several Big Data-AI companies like Stable Diffusion are facing lawsuits for trying to externalize their costs. And ChatGPT has been excoriated for using sweatshops in Africa. The politics of data mining will constantly outstrip the capacity of individual companies to manage, just as is the case with natural resources.
As individual corporations get better at building their own unique knowledge bases and at sourcing algorithms to address internal issues, the edge of internal-scale utility operators like OpenAI (owners of ChatGPT) will start to erode and the real opportunity will shift to enterprise consulting in a balkanised AI business environment. It bears mentioning that becoming a viable competitor to Google’s LLMs in the general knowledge search category is not a socioeconomically transformative step for ChatGPT as the real gap is in specialised knowledge brokerage.
A new kind of “naturalistic fallacy”
Many of the most genuine knowledge breakthroughs are highly counterintuitive. Some clash with contemporary human sensibilities. The more a bot is made contemporaneously human the lower its ability to shift cognitive boundaries. This is hugely important when a bot must make predictions and projections based on judgement-soundness rather than mere factual accuracy.
Confusion in this area caused Soviet and Chinese theoretical Marxists to declare AI a reactionary science well into the 70s. Whilst the Cuban revolutionaries saw only industrial automation and thus embraced AI (popular then as “cybernetics”), the more ideological Marxists understood the challenge it posed to the idea of human transformation itself, on which perfected communism will depend. In that sense, truly groundbreaking LLMs would have to be more unfettered in their probing of human sensibilities than current political and ethical boundaries can contain.
Experiment
To practicalise the above analysis, the author engaged ChatGPT to discuss the prospect of decentralized finance enabling financial inclusion in the developing world. The argument’s vindication is self-evident but a few annotations have been interspersed with the screenshots. The short version is that statistically summarised knowledge drawn from open internet resources is constrained to mimic garden-variety coffee-break conversation rather than serious expert handling of judgement-heavy, high-stakes, decision-making.


ChatGPT does not skip a beat. It continues to parrot the same general platitudes, this time about enlightened co-regulation. It struggles to detect many loaded contexts and not finding many open-internet resources about West Africa – specific crypto regulation debates attempt to bloviate around the subject. Whilst this would be fine when delivered from the stage at a general business conference, it is practically useless from a real decision-maker’s point of view. Improved efficiency in gathering data on the web and the enhanced semantic search will not overcome these limitations. The inquirer’s efforts using prompt-enhancement to improve the quality of the responses depended greatly on the inquirer’s own growing understanding of this LLM limitation suggesting the need for a new breed of, likely expensive, professionals to maximise this tool’s utility.
Latest Stories
-
Toronto chokes under toxic skies as wildfire smoke engulfs the city
9 minutes -
Prayers, Prophecies and Politics: Who’s really working for Ghana’s peace, progress and development?
23 minutes -
Oscar-winning actress Brenda Fricker dies at 81
30 minutes -
NPP pledges to support TikToker Camilla Alhassan’s jail term appeal
42 minutes -
Newborn baby found dead at hotel refuse dump in Wa
43 minutes -
No SHS student will be on double track by 2027—Mahama
52 minutes -
Mahama dismisses third-term speculation, says he is focused on campaign promises
56 minutes -
UHAS set to house one of West Africa’s largest laboratory complexes — Mahama
58 minutes -
Smile Train to convene Africa, India cleft specialists for Indo-Africa Cleft Conference
1 hour -
Parliament extends sitting to Saturday for 2026 Mid-Year Budget Review debate
1 hour -
Come back to Ghanaians, you said they were your children – Mahama tells Ofori-Atta
1 hour -
Kotoko appoint Eric Tinkler as new head coach
1 hour -
Police investigate alleged abduction of 8-month-old baby at Kpando Market
1 hour -
Brand communities and tribal consumption: What football fans teach us about loyalty
1 hour -
Why flee if you’ve done nothing wrong? – Mahama questions Ofori-Atta’s absence
1 hour